
Data comes in all shapes and sizes, and one of today’s main challenges is having it ready for immediate consumption. With us now amid the 4th Industry Revolution (4IR) we are all looking into using the latest and greatest techniques, but are we getting ahead of ourselves? Let us take a moment to think about a common data point journey in the Oil and Gas exploration sector.
A data point’s journey
- Sensor reading.
- Recording of data points.
- Transfer of data to required systems for rig visualization.
- Movement from remote site to town.
- Visualized in town and recorded in a database.
This is of course oversimplifying the process, however what we are trying to point out here is that data is often collected and used for the immediate need. A data point is often not future-proofed or made available in a manner that ensures easy consumption by the myriad of applications and parties involved in the data points lifecycle. So, how do we overcome this to support 4IR applications, all while avoiding an over complicated process and manual intervention?
Two Options are:
- Defining a single standard that everyone must adhere to. This is good in principle but not in practice. Several systems are hardcoded to data specifics and having a single standard can often cause the need for multiple uncontrolled versions of the data, manual overheads and delays in data preparation prior to use.
- Break data into silos. These silos would host differing standards and most likely hosted by different parties. The data can often be duplicated and uncontrolled with access provided outside of intended parties. It can often be extremely difficult to then bring the different data readings together for analysis.
Data Virtualization
At Petrolink, we have found that the best way to combat these issues is the virtualization of the data. We allowed for the same data to be stored and a virtual data configuration to be placed on the data, allowing for mnemonic aliasing and unit conversion. What does this really mean, however? Example:
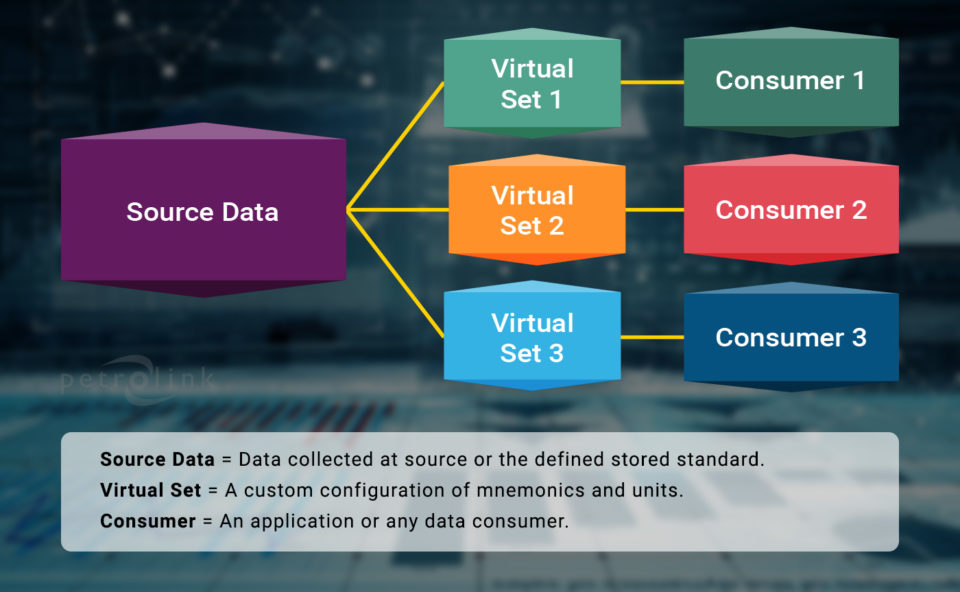
In short, a data standard can be created for all data consumers without data duplication. These virtualized datasets allow for custom mnemonics and units using standard coefficients, all while maintaining the source data in the core standard.
At Petrolink, we have the tools and ability to collect the source data and define the initial standard. We can then define the virtual data logs for consumption by your partners and applications. We know from experience that many applications have locked templates and require mapping to work immediately. We have used this practice internally with great effect to reduce our workloads, avoid data duplication and to collect data immediately ready for use.
If you would like more information or have any questions about this, please contact us!